


Stuart Leitch speaking at the Berlin AI event
Discussion topics included:
- What ethical rules and normative practices do we need to encode in generative AI features or products?
- Given the inherent limitations of GenAI, and cost to quality tradeoffs, how do we determine when a product or feature is good enough to release?
- Practical advice for getting started – what should organizations think about?
As discussed in the Scholarly Kitchen article, the capabilities of a RAG system are heavily impacted by cost, leading to major tensions in solution designs. Cost-quality tensions can generally be bucketed as follows:
- LLM strength: quality and cost are highly correlated. Claude Opus, arguably the strongest model currently, is around 150 times the cost of Mistral’s Mixtral 8x22B, a fast and cheap but respectable model ($15 per million input tokens for Opus compared to 10¢ for Mixtral with 100 tokens equating to around 75 words).
- Depth and breadth of material injected into context window: sophisticated analysis, where the answer can’t just be found from a single authoritative source, often requires a lot of information to be injected into the LLM’s context window. This can require a lot of tokens.
- Sophistication of content preparation: pre-preparation prior to ingestion to weight content for authority and suppress content that could lead to misleading results adds up-front cost. For example, reference sections often yield very high semantic similarity scores but are not sufficient for an LLM to draw conclusions from (although they will happily do so).
- Retrieval strategy: techniques like query rewriting, HyDE, hybrid search, ReACT and FLARE all improve quality at significant additional cost
- Validation strategy: additional steps to check the quality of responses will catch many outliers but adds additional engineering complexity and incur higher token consumption costs
- Sophistication of ranking strategy: adds engineering effort and compute costs of cross-encoding
- Agentic strategies: as frontier models become better at following precise instructions, it is possible to create recursive loops where an agent (or many agents) builds a research plan and forages for information until satisfied. Sophisticated agentic techniques such as FLARE typically incur 10x the token cost of simpler approaches. Within a few generations, it is likely models will have the reasoning abilities and be sufficiently reliable at instruction following to perform comprehensive literature reviews, at potentially unbounded cost.

Leaders join a cocktail reception following the Berlin event for continued discussions
As leaders in your companies, you should be thinking about AI applications in terms of technology S-Curves. Too early and you waste a lot of money. Too late and your competitors have advantage.
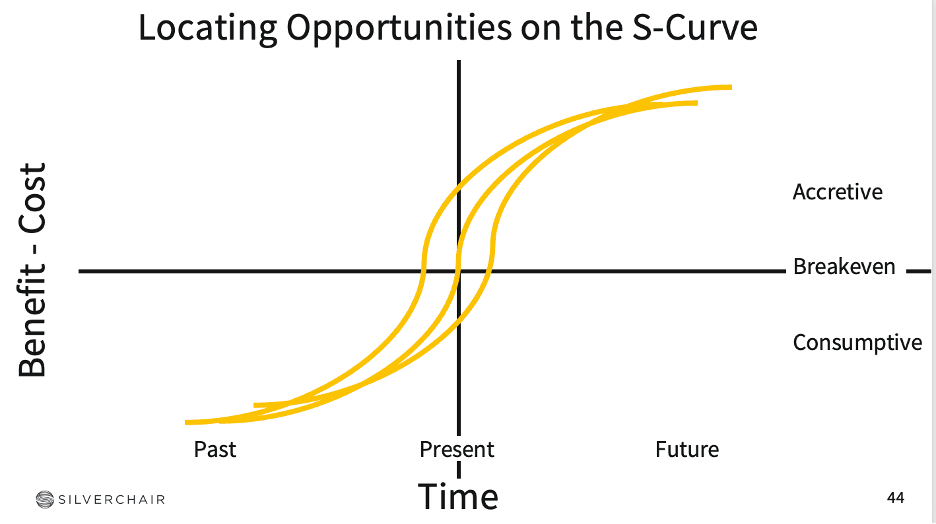
This is not a technology cycle we can sit out, but where we are on the S-Curve depends on the application. For practitioners using beginner or intermediate reference material, the curve us going vertical in this timeframe. Other cases will vary. If we do nothing, most of the value will accrue to larger companies and publishers will simply become licensers and there will be significant disintermediation. There’s a strong current of efforts happening right now in our industry to get ahead of that, which is important given the quality of research content and the value it will bring to those systems.
Ultimately, when is good enough to release is a combination of two factors: 1) the holistic cost of quality, which is heavily contingent on managing user expectations; and 2) the recognition that disruption is coming and if we wait for the optimal quality cost profile, audiences will likely have already substantially migrated to competing services.
The main point is to get closer to the technology and get a better understanding of how it currently performs and how that performance is steadily ticking up while costs are quickly coming down.
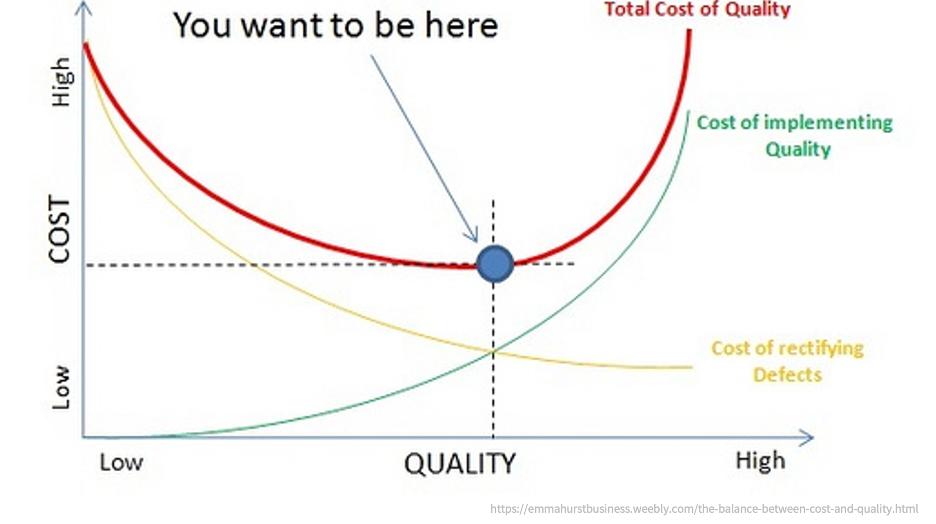
There’s no magical answer, but we as an industry are in a very interesting time. At Silverchair, we tend to be optimistic—there’s a lot of progress happening around benchmarking, around multi-modality, around safeguards and policies, and around overall industry literacy. We expect significant advancements in sophisticated reasoning in the coming months and years, as the various models have caught up to one another and continue to improve behind the scenes.
We don’t know the path these products will take either globally or in our industry, but we remain committed to learning together as a community and sharing our insights.
Want to join the conversation? Join us at Platform Strategies 2024 on September 25th in Washington, DC. Register here by September 1st.